
虽然神经网络具有非常强的表达能力,但是当应用神经网络模型到机器学习时仍然存在一些难点问题。主要分为两大类:
【1.优化问题】:深度神经网络的优化十分困难
(1)神经网络的损失函数是一个非凸函数,找到全局最优解通常比较困难;
(2)深度神经网络的参数通常非常多,训练数据也比较大,因此无法使用计算代价很高的二阶优化方法,而一阶优化方法的训练效率通常较低;
(3)深度神经网络存在梯度消失或爆炸问题,导致基于梯度的优化方法经常失效。
【2.泛化问题】:由于深度神经网络的复杂度比较高,并且拟合能力很强,很容易在训练集上产生过拟合。因此在训练深度神经网络时,需要一定的正则化方法来改进网络的泛化能力。
本文主要从【网络优化】和【网络正则化】两个方面来介绍一些经验方法,从而能够在神经网络的表示能力、复杂度、学习效率和泛化能力之间找到比较好的平衡。具体如下:
网络优化方面:常用的优化算法、参数初始化方法、数据预处理方法、逐层归一化方法、超参数优化方法;
网络正则化方面: 正则化、权重衰减、提前停止、丢弃法、数据增强、标签平滑。
【网络优化】是指寻找一个神经网络模型来使得经验(或结构)风险最小化的过程,包括模型选择以及参数学习等。
神经网络的种类非常多,不同的网络结构非常不同。由于网络结构的多样性,我们很难找到一种通用的优化方法。不同优化方法在不同网络结构上的表现也有比较大的差异。
此外,网络的超参数一般比较多,这也给优化带来很大的挑战
在低维空间中非凸优化的主要难点是如何选择初始化参数和逃离【局部最优点】。深度神经网络的参数非常多,其参数学习是在非常高维空间中的非凸优化问题,其挑战和在低维空间中的非凸优化问题有所不同。
在高维空间中,非凸优化的难点并不在于如何逃离局部最优点,而是如何逃离【鞍点】。
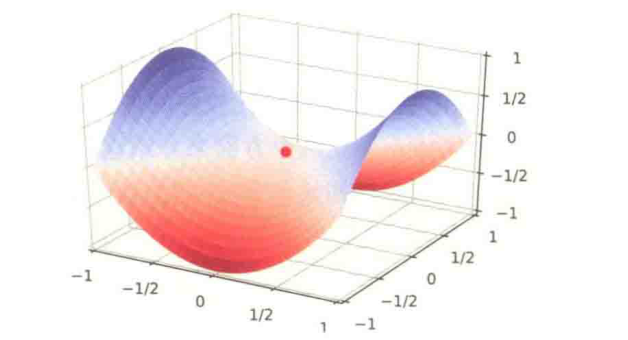
为什么在高维空间中的难点是如何逃离鞍点?
1.
在高维空间中,【局部最小值】要求在每一维度上都是最低点,这种概率非常地低。假设网络有10000维参数,梯度为0的点(即驻点)在某一维上是局部最小值的概率为 ,那么在整个参数空间中,驻点是局部最优点的概率为
,这种可能性非常小。也就是说,在高位空间中大部分驻点都是鞍点。
基于梯度下降的优化方法会在鞍点附近接近于停滞,很难从这些鞍点中逃离。因此,【随机梯度下降】对于高维空间中的非凸优化问题十分重要,通过在梯度方向上引入随机性,可以有效逃离鞍点。
2.
深度神经网络的参数非常多,并且有一定的冗余性,这使得每单个参数对最终损失的影响都比较小,因此会导致损失函数在局部最小解附近通常是一个平坦的区域,称为【平坦最小值(Flat Minima)】。
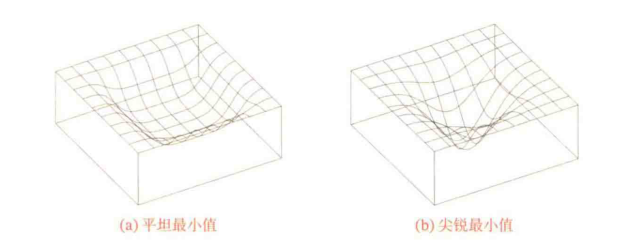
在一个平坦最小值的领域内,所有点对应的训练损失都比较接近,表明我们在训练神经网络时,不需要精确地找到一个局部最小解,只要在一个局部最小解的领域内就够了。
【局部最小解的等价性】:在非常大的神经网络中,大部分的局部最小解是等价的,它们在测试集上性能都比较相似。此外,局部最小解对应的训练损失都可能非常接近于全局最小解对应的训练损失。当一个模型收敛到一个平坦的局部最小值时,其鲁棒性会更好,即微小的参数变动不会剧烈影响模型能力。因此,在训练神经网络时,我们通常没有必要找全局最小值,这反而可能导致过拟合。
改善神经网络优化的目标是找到更好地局部最小值和提高优化效率。目前的改善方法通常由一些几个方面:
(1)使用更有效的优化算法(5.2节)
(2)使用更好地参数初始化方法(5.3节)、数据预处理方法(5.4节)
(3)修改网络结构来得到更好的优化地形(5.5节)
(4)使用更好的超参数优化方法(5.6节)
目前,【深度神经网络】的参数学习主要是通过梯度下降法来寻找一组可以最小化结构风险的参数。在具体实现中,梯度下降法可以分为;批量梯度下降、随机梯度下降以及小批量梯度下降三种形式。
在训练深度神经网络时,训练数据的规模通常都比较大。如果在梯度下降时,每次迭代都要计算整个训练数据上的梯度,这就需要比较多的计算资源。因此,在训练深度神经网络时,经常使用【小批量梯度下降法( Mini-Batch Gradient Descent)】.


从上面的公式可以看出,影响小批量梯度下降法的主要因素有:
(1)批量大小
(2)学习率
(3)梯度估计
为了能够更有效地训练深度神经网络,在标准的小批量梯度下降法的基础上,也经常使用一些改进方法以加快优化速度。本文将分别从【批量大小选择】、【学习率调整】、【梯度估计的修正】这三个方面来介绍在神经网络优化中常用的算法。这些改进算法也可以同样应用在批量或随机梯度下降法上。
一般而言,批量大小不影响随机梯度的期望,但是会影响随机梯度的【方差】。
批量大小越大,随机梯度的方差越小,引入的噪声也越小,训练也越稳定,因此可以设置较大的【学习率】。
批量大小较小时,需要设置较小的【学习率】,否则模型会不收敛。
事实上,学习率通常随着批量大小的增大而相应地增大。一个简单有效的方法是【线性缩放规则】:当批量大小增加m倍时,学习率也增加m倍。
此外,批量大小和模型的返还能力也有一定的关系:批量越大,则越有可能收敛到尖锐最小值;批量越小,越有可能收敛到平坦最小值。
学习率是神经网络优化时重要的超参数,在梯度下降算法中,学习率的取值非常关键,如果过大就不会收敛,如果过小则收敛速度太慢。
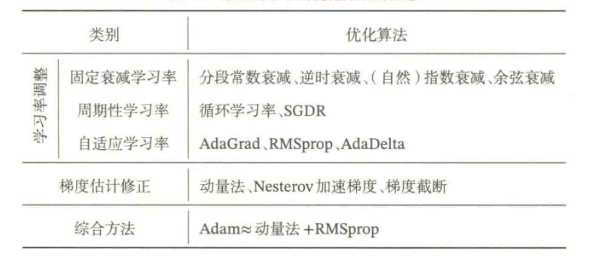
常用的学习率调整方法包括:【学习率衰减】、【学习率预热】、【周期性学习率调整】以及一些【自适应调整学习率】的方法。
(1)学习率衰减
从经验上看,学习率在一开始要保持大些来保证收敛速度,在收敛到最优点附近时要小些以避免来回震荡。比较简单的学习率调整可以通过【学习率衰减(Learning Rate Decay)】的方式来实现,也成为【学习率退火】。
假设初始化学习率为 ,在第
次迭代时的学习率为
。常见的衰减方法有以下几种:
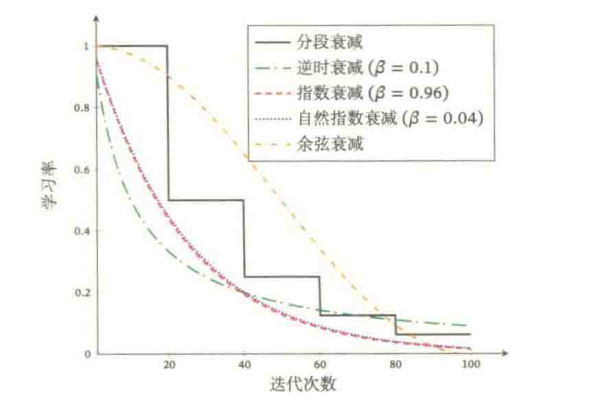
- 【分段常数衰减(Piecewise Constant Decay)】:即每经过
次迭代将学习率衰减为原来的
倍,其中
和
<1为根据经验设置的超参数。分段常数衰减也成为阶梯衰减。
- 【逆时衰减(Inverse Time Decay)】:
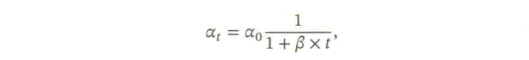
- 【指数衰减(Exponential Decay)】:
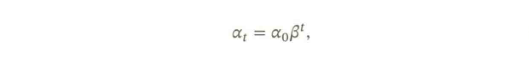
- 【自然指数衰减(Natural Exponential Decay)】:
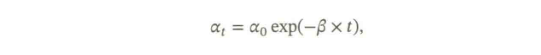
- 【余弦衰减(Cosine Decay)】:
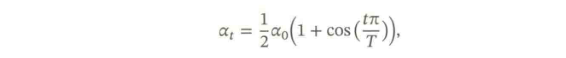
下图给出了不同衰减方法的示例(假设初始学习率为1)
(2)学习率预热
在小批量梯度下降法中,当批量大小的设置比较大时,通常需要比较大的学习率。但在开始训练时,由于参数是随机初始化的,梯度往往也比较大,再加上比较大的学习初始率,会使得训练不稳定。
为了提高训练稳定性,我们可以在最初几轮迭代时,采用比较小的学习率,等梯度下降到一定程度后在回复到初始学习率,这种方法称为【学习率预热(Learning Rate Warmup)】。

(3)周期性学习率调整
为了使得梯度下降法能够逃离鞍点或尖锐最小值,一种经验性的方式是在训练过程中周期性地增大学习率。
当参数处于尖锐最小值附近时,增大学习率有助于逃离尖锐最小值;
当参数处于平坦最小值附近时,增大学习率依然有可能在该平坦最小值的吸引域内。
因此,周期性地增大学习率虽然可能在短期内损害优化过程,使得网络收敛的稳定性变差,但从长期来看有助于找到更好的局部最优解。
下面将介绍两种常用的周期性调整学习率的方法:【循环学习率】和【带热重启的随机梯度下降】。



除了调整学习率之外,还可以进行梯度估计(Gradient Estimation)的修正。
在随机(小批量)梯度下降法中,如果每次选取样本数量比较小,损失会呈现震荡的方式下降。也就是说,随机梯度下降方法中每次迭代的梯度估计和整个训练集上的最优梯度并不一致,具有一定的随机性。
一种有效地缓解梯度估计随机性的方式是通过使用最近一段时间内的平均梯度来代替当前时刻的随机梯度作为参数更新的方向,从而提高优化速度。主要方法有:动量法、Nesterov加速梯度、梯度截断。
本节介绍的几种优化方法大体上可以分为两类:1)调整学习率,使得优化更稳定;2)梯度估计修正,优化训练速度。
下图汇总了本节介绍的几种神经网络常用优化算法:
这些优化算法可以用下面公式来统一描述概括:
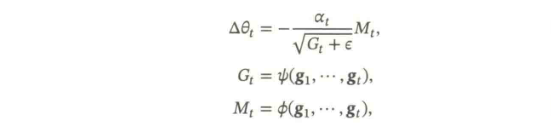

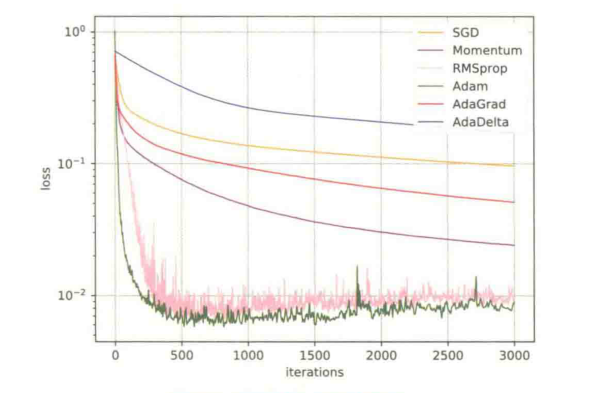
下图给出了这几种优化方法在MNIST数据集上收敛性的比较(学习率为0.001,批量大小为128)
神经网络的参数学习是一个非凸优化问题。当使用梯度下降法来进行优化网络参数时,【参数初始值】的选取十分关键,关系到网络的优化效率和泛化能力。参数初始化的方式通常有以下三种:
(1)预训练初始化(Pre-trained Initialization):不同的参数初始值会收敛不同的局部最优解。一个已经在大规模数据上训练过的模型可以提供一个好的参数初始值,这会使得网络收敛到一个泛化能力高的局部最优解。
(2)随机初始化(Random Initialization):对每个参数都进行随机初始化,使得不同的神经元之间的区分性更好,从而打破在神经网络中隐藏层神经元没有区分性的问题。好的随机初始化方法对训练神经网络模型来说十分重要。这里主要有三种常用的随机初始化方法:【基于固定方差的参数初始化】、【基于方差缩放的参数初始化】、【正交初始化】。
(3)固定值初始化:对于一些特殊的参数,我们可以根据经验用一个特殊的固定值来进行初始化。
一般而言,样本特征由于来源以及度量单位不同,他们的【尺度】(即取值范围)往往差异很大。
不同机器学习模型对数据特征尺度的敏感程度不一样。如果一个机器学习算法在缩放全部或部分特征后不影响它的学习和预测,我们就称该算法具有【尺度不变性】。
对于【尺度敏感】的模型,必须先对样本进行预处理,将各个维度的特征转换到相同的取值空间,并且消除不同特征之间的相关性,才能取得比较理想的结果。
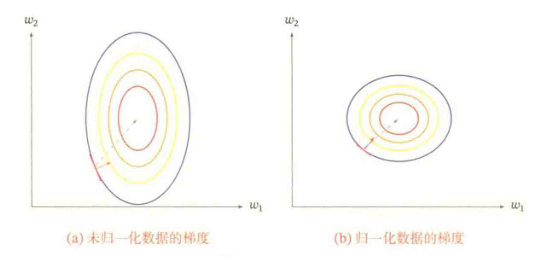
【归一化(Normalization)】方法泛指把数据特征转换为相同尺度的方法,比如把数据特征映射到[0,1]或[-1,1]区间内,或者映射为服从均值为0、方差为1的标准正态分布。主要有如下方法
(1)最小最大值归一化
(2)标准化
(3)白化:降低数据特征之间的冗余性,如使用PCA
【逐层归一化(Layer-wise Normalization)】是将传统机器学习中的数据归一化方法应用到深度神经网络中,对神经网络中隐藏层的输入进行归一化,从而使得网络更容易训练。
(1)更好地尺度不变性
(2)更平滑的优化地形:逐层归一化一方面可以使得大部分神经层的输入处于不饱和区域,从而让梯度变大,避免梯度消失问题;另一方面还可以使得神经网络的优化地形更加平滑,以及使梯度更加稳定,从而允许我们使用更大的学习率,并 提高收敛速度。
常用的逐层归一化方法有:批量归一化、层归一化、权重归一化、局部响应归一化。
常见的超参数有以下三类:
(1)网络结构,包括神经元之间的连接关系、层数、每层的神经元数量、激活函数的类型等。
(2)优化参数,包括优化方法、学习率、小批量的样本数量等
(3)正则化系数
超参数优化(Hyperparameter Optimization)主要存在两方面的困难:
(1)超参数优化是一个组合优化问题,无法像一般参数那样通过梯度下降法来优化,也没有一种通用有效的优化方法;
(2)评估一组超参数配置(Configuration)的时间代价非常高,从而导致一些优化方法在超参数优化中难以应用。

对于超参数的配置,比较简单的方法有【网格搜索】、【随即搜索】、【贝叶斯优化】、【动态资源分配】和【神经架构搜索】。
机器学习模型的关键是【泛化问题】,即在样本真实分布上的期望风险最小化。
由于神经网络的拟合能力非常强,其在训练数据上的错误了往往都可以降到非常低,甚至可以到0,从而导致过拟合。因此,如何提高神经网络的泛化能力反而称为影响模型能力的最关键因素。
【正则化(Regularization)】是一类通过限制模型复杂度,从而避免过拟合,提高泛化能力的方法,比如引入约束、增加先验、提前停止等。
L1和L2正则化是机器学习中最常用的正则化方法,通过约束参数的的L1和L2范数来减小模型在训练数据集上的过拟合现象。


关于L1和L2正则化还可参考以下文章:
莫烦:什么是 L1/L2 正则化 (Regularization)bingo酱:L1正则化与L2正则化权重衰减(Weight Decay)是一种有效的正则化方法,在每次参数更新时,引入一个衰减系数。
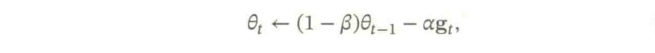


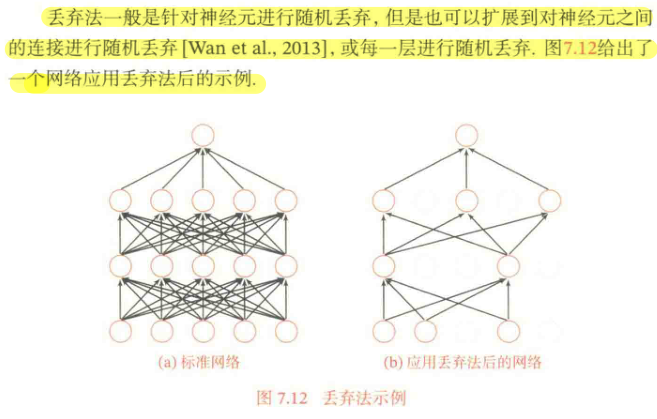
深度神经网络一般需要大量的训练数据才能获得比较理想的效果。在数据量有限的情况下,可以通过【数据增强】老增加数据量,提高模型鲁棒性,避免过拟合。目前,数据增强还主要应用在图像数据上,在文本等其他数据上还没有太好的办法。
【标签平滑】即在输出标签中增加噪声来避免模型过拟合。
深度神经网络优化和正则化是既对立又统一的关系。一方面我们希望优化算法能找到一个全局最优解;另一方面我们又不希望模型优化找到最优解,这可能陷入过拟合。优化和正则化的统一目标是期望风险最小化。
在优化方面。训练神经网络的主要难顶是非凸优化和梯度消失问题。提高训练效率的方法主要有以下3个方面:1)修改网络以获得更好地优化地形,比如使用逐层归一化;2)使用更有效的优化算法;3)使用更好地参数初始化方法。

